Mettre en place une base de données relationnelle
📚 Références
- REAC (mise à jour du 03/07/2024), pages 23 et 24
- RE (mise à jour du 03/07/2024), page 11
📋 En résumé
Le front-end : c'est fini !
Mais avant de nous attaquer au back-end d'un point de vue code, on va voir ce qui est attendu dans cette CP qui parle de la mise en place d'une base de données relationnelle.
J'aurai aimé te dire que oui, mais ça va être un poil trop léger pour cette compétence...
Mais garde sous la main ta base de données non relationnelles
pour la prochaine compétence, ça te servira 😉
🎨 Modélisation de la base de données
Commençons par le commencement : comment créer une base de données relationnelle ?
Il y a pléthore de possibilités, mais ici on va s'attarder sur une méthodologie française (cocorico 🐓) qui est la méthode Merise.
On va se baser sur différents schémas issus de cette méthode pour créer notre base de données relationnelle, à savoir :
- Le dictionnaire des données : qui va recenser toutes les données que l'on va stocker par la suite dans notre base de données
- Le MCD (Modèle Conceptuel des Données) : qui va représenter les données et leurs relations, sous la forme d'entités et d'associations dans un schéma graphique
- Le MLD (Modèle Logique des Données) : qui va représenter les données sous forme de tables et de relations, dans un schéma graphique
- Le MRD (Modèle Relationnel des Données) : qui va représenter les mêmes informations que le MLD, mais cette fois-ci en format texte
- Le MPD (Modèle Physique des Données) : qui va représenter les données sous forme de tables et de relations, en intégrant les types de données et les contraintes
Tu remarqueras que j'y ai indiqué un ordre dans la liste ci-dessus.
Si je peux te donner un indice : ce n'est pas pour rien que c'est une liste ordonnée 😉
Donc si tu réalises un dictionnaire de données après avoir fait ton MPD, c'est que tu n'as pas compris l'objectif du dictionnaire de données ! (par exemple)
🗂️ Le dictionnaire des données
L'objectif du dictionnaire des données est de recenser toutes les données que l'on va stocker dans notre base de données.
L'idée est qu'il soit très simple et compréhensible par tout le monde, même par quelqu'un qui n'y connaît rien en base de données.
Exemple de dictionnaire de données
| Nom de la donnée | Format de la données | Longueur maximale attendue | Description de la donnée | Exemple de donnée |
|---|---|---|---|---|
| Numéro d'identification du salarié | Alphanumérique | 30 | - | - |
| Prénom du salarié | Alphabétique | 30 | - | Jean |
| Nom du salarié | Alphabétique | 30 | - | Dupont |
| Adresse email du salarié | Alphanumérique | 50 | - | jean.dupont@exemple.fr |
| Adresse postale du salarié | Alphanumérique | 60 | - | 1 rue de la Paix |
| Code postal du salarié | Alphanumérique | 5 | - | 75000 |
| Ville du salarié | Alphabétique | 30 | - | Paris |
| Mot de passe du salarié | Alphanumérique | 80 | Mot de passe sécurisé (hashé) | - |
... et ainsi de suite pour toutes les données que tu vas stocker dans ta base de données.
On peut constater qu'on ne fait apparaître aucun terme technique, on se contente de décrire les données de manière simple et compréhensible. Grossièrement, voici les formats que l'on peut retrouver dans un dictionnaire des données :
- Alphabétique : pour les chaînes de caractères contenant uniquement des lettres
- Alphanumérique : pour les chaînes de caractères contenant des lettres et des chiffres
- Numérique : pour les nombres
- Date : pour les dates
- Vrai/Faux : pour les données booléennes
Mais pourquoi le code postal est marqué en alphanumérique ? 🤔
C'est une très bonne question figure-toi !
En France, le code postal est composé de 5 chiffres, mais il peut arriver que certains codes postaux commencent par un zéro.
Or, si on stocke le code postal en numérique, on risque de perdre ce zéro au début du code postal.
Exemple :
75000->7500001000->1000(on a perdu le zéro au début)
On retrouve également ce cas de figure pour les numéros de téléphone, qui peuvent commencer par un zéro.
Toutefois il faut également prendre en compte quelque chose... ici, l'exemple ne concerne que la France.
Si demain on te demande de prévoir le fait que ton application puisse être utilisée dans un autre pays, il faudra peut-être revoir ce choix de format pour le code postal.
Certains pays ont des codes postaux composés de lettres et de chiffres, d'autres vont avoir jusqu'à 9 caractères, etc.
⬇️ Cas de figure spécifique, et pourtant très important à connaître ⬇️
Prenons l'exemple où l'on fait une application pour la France uniquement.
En France, on considère que l'indicatif des numéros de téléphone est +33. On serait donc tenté de se dire :
"Pas besoin de stocker l'indicatif puisque je veux uniquement enregistrer des numéros de téléphones français."
Hmm.. vraiment ?
Pourtant : la Réunion, la Guadeloupe, la Martinique, la Guyane et Mayotte sont bien des départements français, non ?
En regardant de plus près, les numéros de téléphone de ces départements ne commencent pas par +33 mais par +262 pour la Réunion, +590 pour la Guadeloupe, etc.
Il te faudra donc stocker les numéros de téléphone avec 13 caractères (ou plus) pour être sûr de ne pas perdre d'informations et t'assurer que ton application puisse être utilisée partout en France et/ou dans le monde selon les besoins !
Conclusion de ce pavé :
Pensez à vous renseigner sur les pays que vous ciblez pour votre application, ça peut vous éviter des erreurs de conception 😉
📊 Le MCD
Tout comme le dictionnaire des données, le MCD a pour objectif de représenter les données et leurs relations, mais cette fois-ci sous forme graphique. On va également découper davantage nos données en les faisant apparaître dans des entités distinctes.
On fera attention à ne pas être technique, comme pour le dictionnaire des données, et on va se contenter de représenter les données et leurs relations. Ce document est avant tout destiné à être compris par tout le monde, notamment le client final.
Exemple de MCD
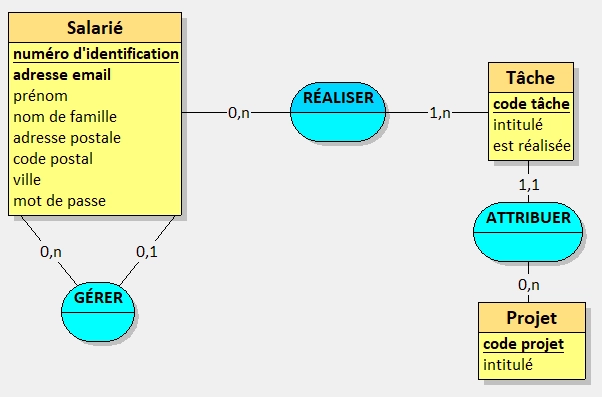
Sur ce schéma, on peut distinguer deux entités : Salarié et Congé. Elles sont représentées par des rectangles et contiennent leurs différentes propriétés.
On peut également remarquer d'autres éléments, comme des "bulles" bleues qui représentent les relations entre les entités. On y retrouve des verbes à l'infinitif qui décrivent la relation entre les entités.
Mais entre ces verbes et les entités, il y a des chiffres (et parfois un n qui se balade), ce sont les fameuses cardinalités.
Ce schéma nous apprend donc que :
Salarié- GÉRER -Salarié(Relation réflexive)- Un même salarié peut gérer plusieurs autres salariés (
Salarié0,n - GÉRER -Salarié0,1) - Un salarié peut n'avoir aucun ou qu'un seul manager (
Salarié0,1 - GÉRER -Salarié0,n)
- Un même salarié peut gérer plusieurs autres salariés (
Salarié- RÉALISER -Tâche- Un salarié peut réaliser plusieurs tâches (
Salarié0,n - RÉALISER -Tâche1,n) - Une tâche est réalisée par un ou plusieurs salariés (
Tâche0,n - RÉALISER -Salarié1,n)
- Un salarié peut réaliser plusieurs tâches (
Tâche- ATTRIBUER -Projet- Une tâche est attribuée à un seul projet (
Tâche1,1 - ATTRIBUER -Projet0,n) - Un projet peut contenir plusieurs tâches (
Projet0,n - ATTRIBUER -Tâche1,1)
- Une tâche est attribuée à un seul projet (
Mais pourquoi il n'y a pas les ID dans le schéma ? 🤔
Ni les clés étrangères d'ailleurs...
Tout simplement parce que les ID ne sont pas des données à proprement parler.
Ce sont avant tout des identifiants qui permettent de différencier les entités entre elles, d'un point de vue technique.
Sauf s'il s'agit d'une donnée concrète (comme le numéro de badge de salarié, un numéro de sécurité sociale, un ISBN pour un livre, etc.),
on ne les fait pas apparaître dans le MCD. Cependant, on peut noter que ce n'est pas pour autant que nous n'avons pas de discriminant dans nos entités !
On peut très bien voir la propriété adresse email dans l'entité Salarié qui pourrait servir de discriminant, puisque chaque salarié a une adresse email unique.
Ce document peut être réalisé à l'aide de divers outils, mais je vous recommande chaudement le logiciel Looping qui est gratuit et très simple d'utilisation.
Certes... il semble tout droit sorti des années 90, mais il est adapté à la réalisation de schémas de la méthodologie Merise !
Et si tu utilises ou utilisais Mocodo, fais très attention ! Certes, l'outil est très puissant et permet tout de même de réaliser des MCD, mais contrairement à Looping il ne va pas t'imposer de respecter les règles de la méthode Merise.
Pratique d'un côté, mais pas fiable donc... à moins que tu sois un⸱e expert⸱e en Merise et que tu veuilles te passer de Looping !
📈 Le MLD
Cette fois-ci, on va passer à la vitesse supérieure en représentant nos données sous forme de tables et de relations !
Les termes techniques ont alors entièrement leur place dans ce document, puisqu'il est destiné aux développeurs qui vont mettre en place la base de données.
Exemple de MLD
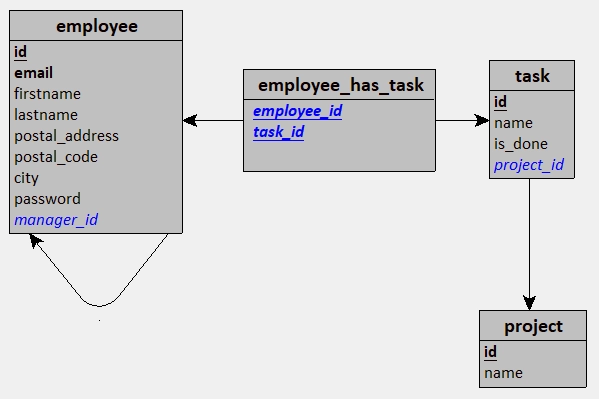
Et voilà un peu de changement !
Déjà, on peut dire au revoir aux entités et aux relations, et bonjour aux tables et aux clés étrangères 🎉 !
On peut aussi voir que certaines de nos propriétés ont changé de nom, comme numéro d'identification de l'entité Salarié qui est devenu id pour la table employee.
On peut également voir que nos relations ont été transformées en clés étrangères, qui permettent de lier nos tables entre elles et si nécessaire : en table de jointure (comme pour la relation Salarié - RÉALISER - Tâche).
Et pour finir : tous les termes ont été traduits du français vers l'anglais.
De manière simple : il n'y a pas de règle. Cependant, il est recommandé d'utiliser une seule langue pour nommer les tables, les colonnes, les clés, etc dans une base de données.
Pour choisir cette langue, il est recommandé de se baser sur la langue de travail de l'entreprise ou de l'équipe de développement.
Si tu travailles exclusivement avec des francophones : tu as bien évidemment le droit de nommer tes tables et colonnes en français.
Cependant, si au moindre moment tu as besoin de travailler avec des anglophones ou des personnes qui ne sont pas francophones : Shakespeare sera ton ami 📜
(Bon, si tu travailles dans une entreprise espagnole, tu peux aussi opter pour l'espagnol à contrario du français... mais tu as compris l'idée)
Le plus important dans l'histoire, c'est d'être cohérent dans le choix de la langue utilisée.
Tu as commencé par utiliser de l'anglais pour parler des éléments techniques ? Alors tu te dois de tout faire en anglais.
📑 Le MRD
La plupart du temps, le MRD est réalisé sous le nom de MLD mais en format texte.
En réalité, le MRD est la représentation textuelle du MLD.
Mais si ça te rassure, on ne t'en voudra pas si tu parles de "MLD" à la place de "MRD" 😅
On peut donc dire qu'au choix, on peut soit faire un MLD sous forme de schéma, soit sous forme de texte (et dans ce cas, on parle de MRD).
Mais si tu as l'occasion de faire les deux, c'est encore mieux !
Exemple de MRD
employee(id, email, firstname, lastname, postal_address, postal_code, city, password, #manager_id);
project(id, name);
task(id, name, is_done, #project_id);
employee_has_task(#employee_id, #task_id);
Si tu veux comprendre pourquoi certains éléments sont en gras, en italique ou soulignés, voici un court résumé :
- Sous-ligné : Clé primaire (en gras également car unique, voir ci-dessous)
- Gras : Donnée unique au sein de la table
- Italique : Clé étrangère
📦 Le MPD
Maintenant on ne rigole plus, on met les mains dans le cambouis ! 🧑🔧
Puisque tous nos schémas sont prêts, on va pouvoir passer à la création de notre base de données.
Mais si on y repense, notre MLD représente déjà bien notre base de données, non ?
Pas entièrement... car il nous manque les types de données !
Si on reprend notre dictionnaire des données, on avait pu inscrire "Alphabétique" et d'autres formats génériques pour nos données. Mais ces termes n'existent pas (du moins, pas tous) dans les bases de données.
Selon le SGBD que tu utilises, les types de données peuvent varier. Il est donc obligatoire que tu te réfères à la documentation de ton SGBD pour connaître les types de données disponibles 😉
Au passage, le MPD peut se décliner dans deux formats :
- Le format texte : qui reprend les informations du MLD en y ajoutant les types de données et les contraintes. En réalité, il s'agira d'un script SQL qui permettra de créer la base de données et toutes ses tables.
- Le format graphique : qui reprend les informations du MLD en y ajoutant les types de données et les contraintes, mais sous forme de schéma.
Cependant je mets en garde sur le format graphique et la notation que peuvent proposer certains logiciels. Vous avez peut-être eu l'occasion de voir des schémas avec des carrés, des ronds, des losanges ou encore des pattes de corbeau... Cette notation est propre à un langage de modélisation, le UML (Unified Modeling Language), qui ne correspond pas à la méthode Merise.
Dans la méthode Merise, on utilisera simplement des lignes pleines pour représenter les relations entre les tables, et des carrés pour représenter les tables. On retrouvera tout de même des lignes fléchées pour illustrer nos relations dans le MLD, mais c'est tout.
UML est un excellent langage de modélisation, mais on y reviendra davantage dans le cursus CDA 😉
Exemple de MPD (SQL)
CREATE TABLE employee(
id CHAR(30),
email VARCHAR(320),
firstname VARCHAR(30),
lastname VARCHAR(30),
postal_address VARCHAR(60),
postal_code CHAR(5),
city VARCHAR(30),
password CHAR(80),
manager_id CHAR(30),
CONSTRAINT employee_pk PRIMARY KEY (id),
CONSTRAINT employee_ak UNIQUE (email),
CONSTRAINT employee_manager_fk FOREIGN KEY (manager_id) REFERENCES employee(id)
);
CREATE TABLE project(
id CHAR(30),
name VARCHAR(255),
CONSTRAINT project_pk PRIMARY KEY (id)
);
CREATE TABLE task(
id CHAR(30),
name VARCHAR(255),
is_done BOOLEAN,
project_id CHAR(30),
CONSTRAINT task_pk PRIMARY KEY (id),
CONSTRAINT task_project_fk FOREIGN KEY (project_id) REFERENCES project(id)
);
CREATE TABLE employee_has_task(
employee_id CHAR(30),
task_id CHAR(30),
CONSTRAINT employee_has_task_pk PRIMARY KEY (employee_id, task_id),
CONSTRAINT employee_has_task_employee_fk FOREIGN KEY (employee_id) REFERENCES employee(id),
CONSTRAINT employee_has_task_task_fk FOREIGN KEY (task_id) REFERENCES task(id)
);
💾 Sauvegardes de la base de données
C'est bien beau de créer une base de données, mais si on ne la sauvegarde pas, on risque de tout perdre en cas de problème...
Certains hébergeurs permettent de faire des sauvegardes automatisées, mais dans le cas où tu dois toi-même sauvegarder ta base de données, il existe plusieurs solutions :
- Les sauvegardes manuelles : qui consistent à exporter le contenu de ta base de données dans un fichier (généralement au format SQL)
- Les sauvegardes automatiques : qui consistent à automatiser le processus de sauvegarde, généralement via un script ou un outil dédié
On va se concentrer (que très rapidement, ne t'inquiète pas !) sur la partie automatisée, puisqu'elle permet également de comprendre comment faire une sauvegarde manuellement.
Pour mettre en place l'automatisation, on peut mettre en place une tâche planifiée : un processus qui va s'exécuter à intervalles réguliers pour sauvegarder notre base de données.
Sur Linux, on parlera d'un cron job (ou tâche cron en français).
Sans rentrer dans les détails de configuration d'une tâche cron, on va devoir la créer en donnant plusieurs informations :
- Le chemin vers le script de sauvegarde : qui va contenir les commandes pour sauvegarder notre base de données
- La fréquence d'exécution : qui va déterminer à quelle fréquence notre tâche va s'exécuter (toutes les heures, tous les jours, toutes les semaines, etc.)
- Le compte utilisateur : qui va exécuter la tâche, généralement le compte de l'utilisateur qui a les droits d'accès à la base de données
Exemple de script bash pour sauvegarder une base de données PostgreSQL
bash pour sauvegarder une base de données PostgreSQL#!/bin/bash
# Variables
DB_USER="user"
DB_NAME="database"
BACKUP_DIR="/path/to/backup"
DATE=$(date +"%Y%m%d%H%M%S")
# Création du répertoire de sauvegarde
mkdir -p $BACKUP_DIR
# Sauvegarde de la base de données
pg_dump -U $DB_USER $DB_NAME > $BACKUP_DIR/$DB_NAME-$DATE.sql
Ce script va permettre de sauvegarder une base de données PostgreSQL en exportant son contenu dans un fichier SQL.
Il est important de remplacer les variables DB_USER, DB_NAME et BACKUP_DIR par les informations de ta base de données.
Une fois ce script créé, il suffira de le rendre exécutable et de le planifier dans une tâche cron pour automatiser la sauvegarde de ta base de données.
Exemple de tâche cron pour automatiser la sauvegarde
# Ouvrir le fichier de tâches cron
crontab -e
# Ajouter la tâche de sauvegarde, toutes les nuits à minuit
0 * * * * /path/to/backup.sh
Et voilà ! Ta base de données sera sauvegardée toutes les nuits à minuit, sans que tu aies besoin d'intervenir manuellement.
🛡️ Sécurité et confidentialité des données
On ne le répétera jamais assez, mais la sécurité et la confidentialité des données sont primordiales pour toute application.
Pour garantir la sécurité de ta base de données, il est recommandé de mettre en place plusieurs mesures :
- Les sauvegardes régulières : pour éviter de perdre des données en cas de problème
- Les mises à jour régulières : pour corriger les failles de sécurité et les bugs
- Les accès restreints : pour limiter l'accès à la base de données aux seules personnes autorisées
- Les mots de passe forts : pour éviter les attaques par force brute ou par dictionnaire
- Les connexions sécurisées : pour éviter les interceptions de données
Mais la sécurité ne s'arrête pas là, il est également important de garantir la confidentialité des données :
- Le chiffrement des données : pour éviter que des tiers puissent lire les données stockées, en cas de fuite
Même en développement sur ta machine locale, prend l'habitude de ne jamais utiliser les identifiants par défaut de ta base de données (comme root sans mot de passe par exemple).
L'objectif est de te mettre dans les conditions réelles d'un environnement de production, où la sécurité est primordiale. Ça t'évitera de prendre de mauvaises habitudes qui pourraient te coûter cher par la suite.
🎯 Critères d'évaluation
- Les données du schéma conceptuel et leurs relations sont identifiées et prises en compte
- Le schéma physique est conforme aux besoins exprimés dans le dossier de conception et respecte les règles des bases de données relationnelles
- Les règles de nommage sont respectées
- La sécurité, l'intégrité et la confidentialité des données est assurée
- La base de données de tests mise en place est conforme au schéma physique
- Les utilisateurs sont créés avec leurs droits respectifs conformément au dossier de conception
- La base de données créée est sauvegardée et elle peut être restaurée en cas d'incident
- La documentation technique des bases de données est comprise, en langue française ou anglaise (niveau B1 du CECRL pour l'anglais)
🤯 Aller plus loin (hors référentiel)
Pas trop mal à la tête ? On continue un tout petit peu ? 😅
Tu as vu qu'on précise entre parenthèses la longueur des données, mais pourquoi on fait ça ?
Tu n'es pas sans savoir que pour stocker des données et que pour les stocker, il nous faut de l'espace.
Et cet espace, on le définit en fonction de la longueur de nos données : on parle alors d'allocation.
En précisant une valeur entre les parenthèses, on vient dire à notre SGBD combien de place il doit réserver pour stocker nos données au maximum.
Dans le cas d'un VARCHAR(30), on réserve 30 caractères pour stocker notre donnée, même si elle n'en fait que 5 (allocation dynamique).
Dans le cas d'un CHAR(30), on réserve également 30 caractères, mais cette fois-ci on "complète notre donnée avec des espaces" pour atteindre les 30 caractères (allocation statique).
Si on ne précise pas de longueur, le SGBD va réserver une place par défaut qui varie d'un SGBD à l'autre.
Donc ce n'est pas parce que tu te dis : "255 caractères c'est très bien pour mon VARCHAR, pas besoin de le préciser puisque c'est la valeur par défaut !" que tu as raison... 😅
Si demain la norme change et que l'allocation par défaut pour les types VARCHAR passe à 100 caractères au lieu de 255 caractères, tu risques de te retrouver avec des données tronquées !
🧠 Documentations
- Éditions ENI - Merise - Guide pratique (4e édition), par Jean-Luc Baptiste
- Medium - Non, les ID n'ont pas leur place dans un MCD, par Jean Prulière
- SQL.sh - Cours et tutoriels SQL
- Wikip�édia - UML